Explainable Heart Sound Classification Using MFCC-Based Deep CNNs
Explainable Heart Sound Classification Using MFCC-Based Deep CNNs
Overview
This project focuses on developing an automated heart sound classification system to distinguish between normal and abnormal cardiac signals using phonocardiogram (PCG) recordings. The system integrates signal processing and deep learning to provide a scalable and non-invasive solution for early detection of cardiac abnormalities.
By transforming raw audio signals into structured time–frequency representations and leveraging convolutional neural networks, the system enables reliable classification suitable for use as a screening tool in clinical settings.
Problem
Manual interpretation of heart sounds requires clinical expertise and is often affected by:
- Noisy and inconsistent recording environments
- Variability in heart sound patterns
- Limited access to trained specialists
These challenges motivate the need for an automated, robust, and interpretable classification system.
Methodology
The system follows a structured pipeline:
1. Signal Preprocessing
- Segmented PCG signals into standardized 3-second windows
- Used S1 transition detection to align cardiac cycles
- Reduced variability across recordings
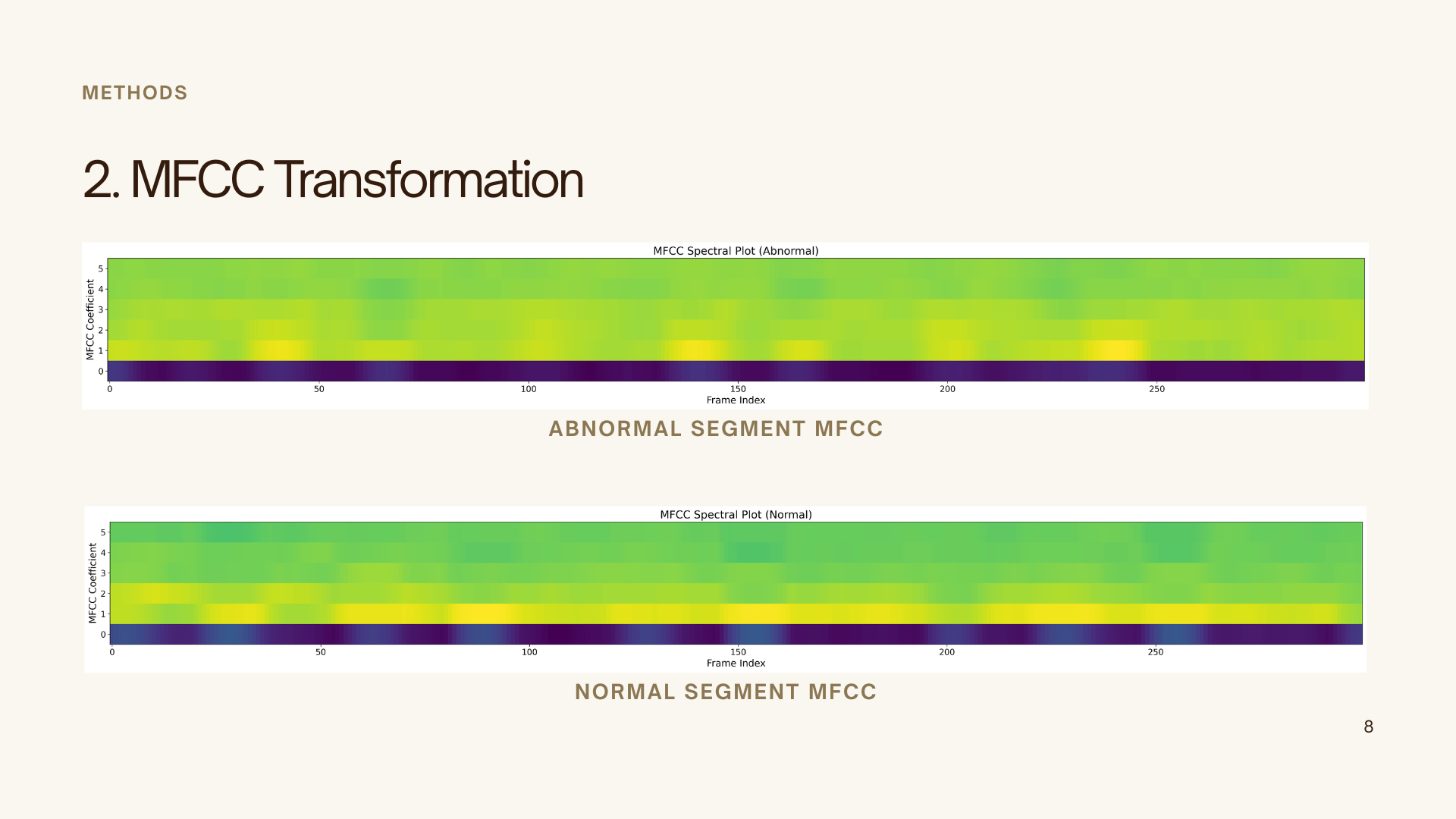
2. Feature Extraction (MFCC)
- Extracted Mel-Frequency Cepstral Coefficients (MFCCs)
- Converted 1D signals into 2D heatmap representations (6 × 300)
- Captured perceptually relevant frequency features
 8.png
8.png
3. Classification using CNN
- Designed a CNN with convolution and pooling layers
- Applied dropout and L2 regularization to reduce overfitting
- Tuned hyperparameters for optimal performance
Challenges & Improvements
One of the key challenges in this project was the low quality and variability of clinical recordings, which introduced noise and inconsistencies in the dataset. This was addressed through careful preprocessing, segmentation, and feature engineering to ensure meaningful and consistent inputs to the model.
Another significant challenge was class imbalance (approximately 80% normal vs 20% abnormal samples), which required careful model training and evaluation strategies to avoid biased predictions.
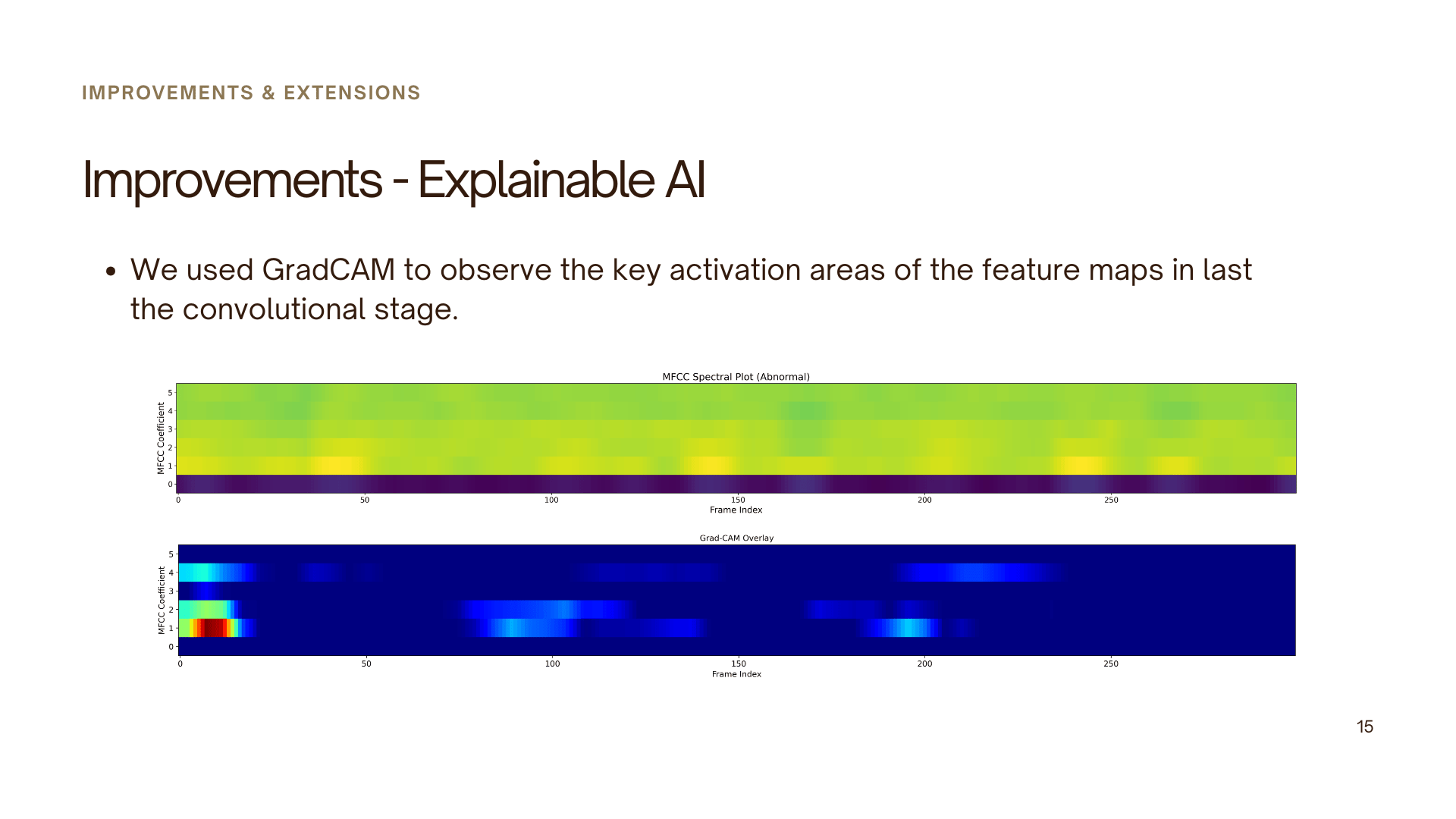
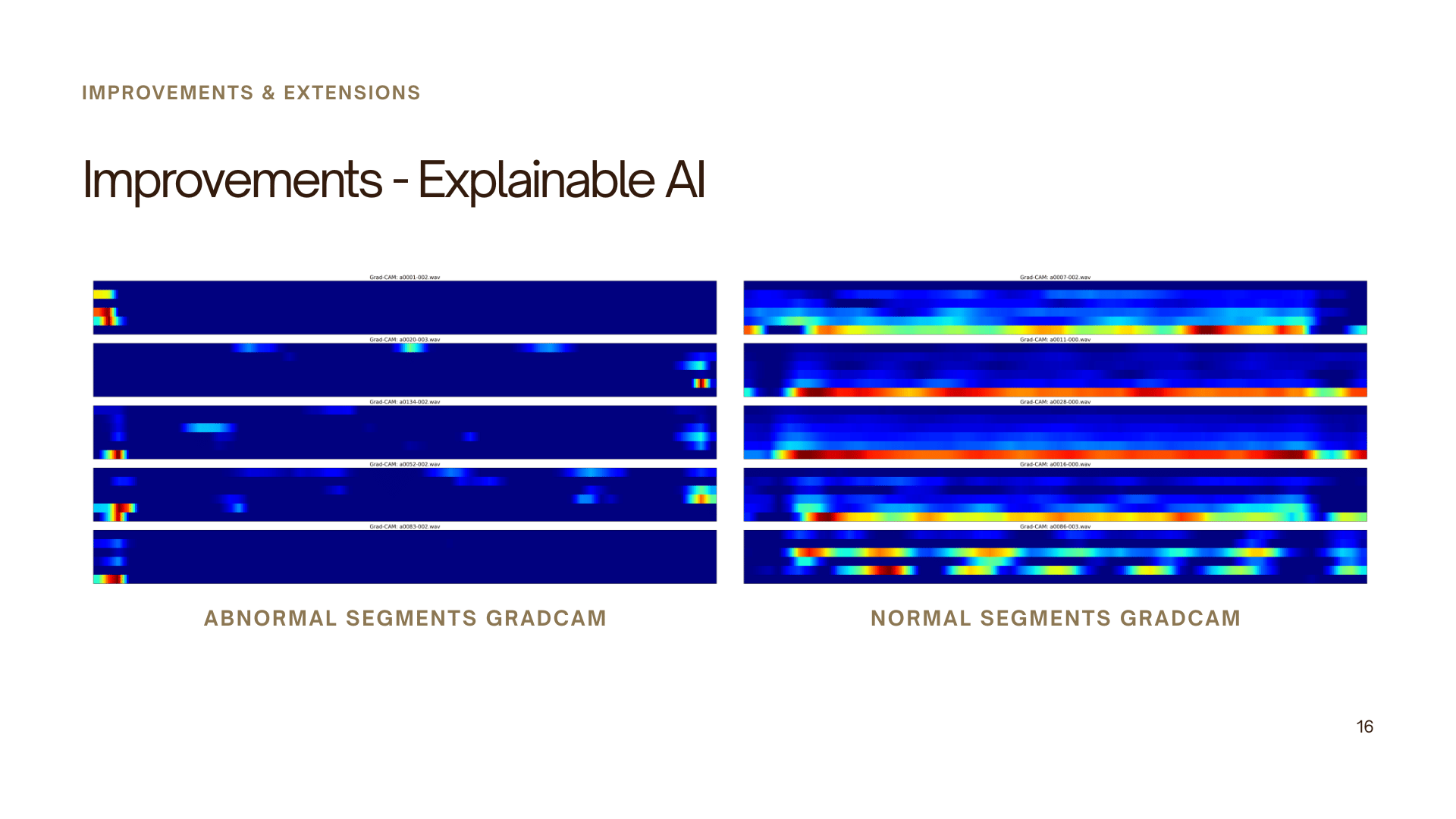
Novel Contribution – Explainability
To address the limitations of black-box deep learning models, an explainability component was introduced using gradient-based visualization techniques (e.g., Grad-CAM).
This allowed visualization of the regions within the MFCC representations that influenced the model’s decisions, providing insights into how the model distinguishes between normal and abnormal heart sounds.
 16.png
16.png
 17.png
17.png
This addition improves:
- Model transparency
- Clinical trustworthiness
- Interpretability of predictions
Dataset
- PhysioNet 2016 Challenge dataset
- ~3,240 heart sound recordings
- Labels: Normal vs Abnormal
- Variable durations (5s–120s)
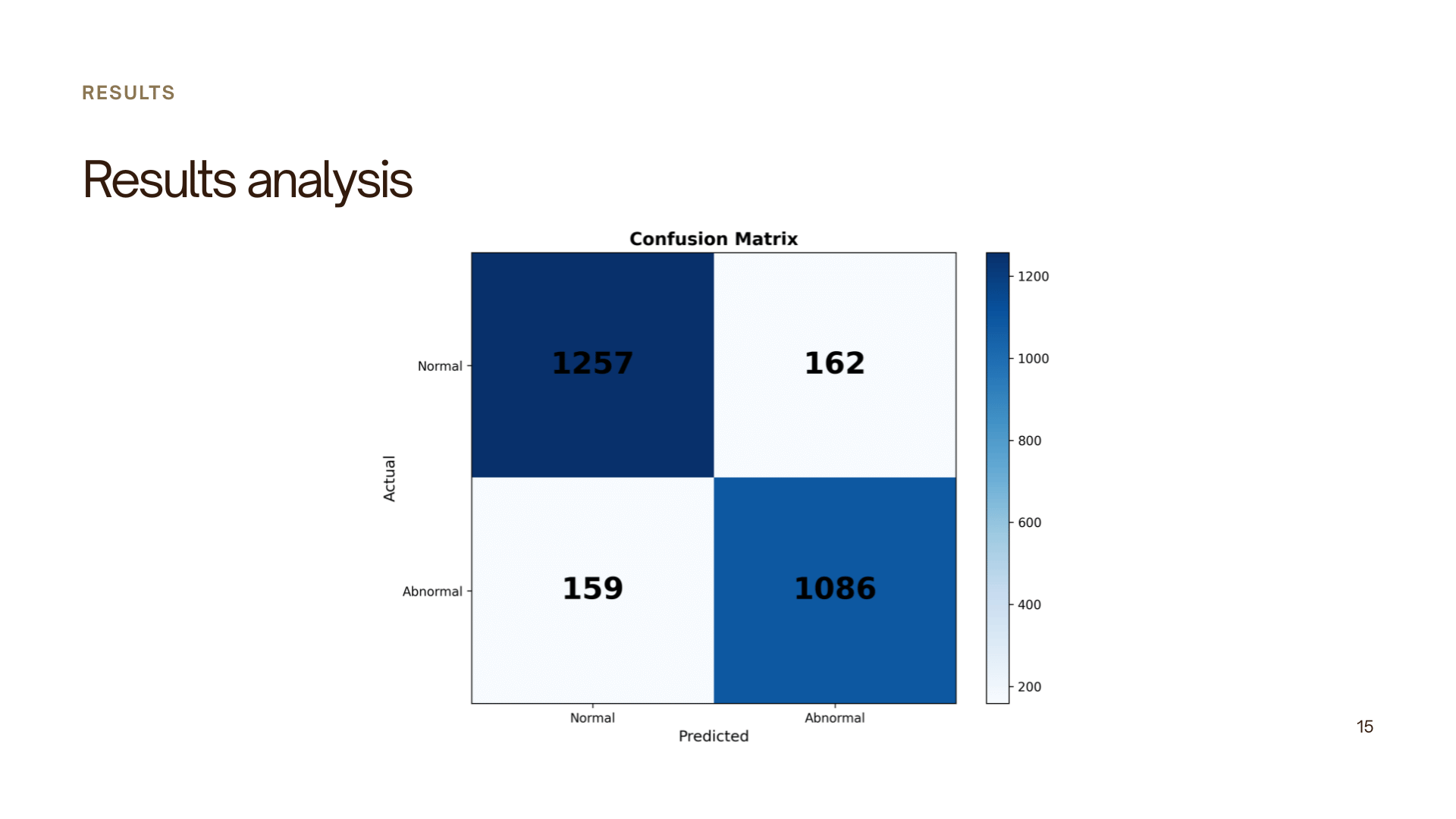
Results
- Accuracy: 84.8%
- Sensitivity: 76.5%
- Specificity: 93.1%
 12.png
12.png
The model demonstrates strong performance for screening-level cardiac abnormality detection.
Technologies Used
- Python
- PyTorch
- Librosa
- Signal processing techniques (MFCC)
- GPU-based training
My Contribution
- Contributed in designed full signal processing pipeline
- Performed data preprocessing and segmentation
- Made the model inference and usage pipeline
- Conducted model evaluation and optimization